
CockroachDB backups operate as jobs, which are potentially long-running operations that could span multiple SQL sessions. Unlike regular SQL statements, which CockroachDB routes to the optimizer for processing, a BACKUP statement will move into a job workflow. A backup job has four main phases:
The Overview section that follows provides an outline of a backup job's process. For a more detailed explanation of how a backup job works, read from the Job creation phase section.
Overview
At a high level, CockroachDB performs the following tasks when running a backup job:
- Validates the parameters of the
BACKUPstatement then writes them to a job in the jobs system describing the backup. - Based on the parameters recorded in the job, and any previous backups found in the storage location, determines which key spans and time ranges of data in the storage layer need to be backed up.
- Instructs various nodes in the cluster to each read those keys and writes the row data to the backup storage location.
- Records any additional metadata about what was backed up to the backup storage location.
The following diagram illustrates the flow from BACKUP statement through to a complete backup in cloud storage:
Job creation phase
A backup begins by validating the general sense of the proposed backup.
Let's take the following statement to start the backup process:
BACKUP DATABASE movr INTO 's3://bucket' WITH revision_history;
This statement is a request for a full backup of the movr database with the revision_history option.
CockroachDB will verify the options passed in the BACKUP statement and check that the user has the required privileges to take the backup. The tables are identified along with the set of key spans to back up. In this example, the backup will identify all the tables within the movr database and note that the revision_history option is required.
The ultimate aim of the job creation phase is to complete all of these checks and write the detail of what the backup job should complete to a job record.
If a detached backup was requested, the BACKUP statement is complete as it has created an uncommitted, but otherwise ready-to-run backup job. You'll find the job ID returned as output. Without the detached option, the job is committed and the statement waits to return the results until the backup job starts, runs (as described in the following sections), and terminates.
Once the job record is committed, the cluster will try to run the backup job even if a client disconnects or the node handling the BACKUP statement terminates. From this point, the backup is a persisted job that any node in the cluster can take over executing to ensure it runs. The job record will move to the system jobs table, ready for a node to claim it.
Resolution phase
Once one of the nodes has claimed the job from the system jobs table, it will take the job record’s information and outline a plan. This node becomes the coordinator. In our example, Node 2 becomes the coordinator and starts to complete the following to prepare and resolve the targets for distributed backup work:
- Test the connection to the storage bucket URL (
's3://bucket'). - Determine the specific subdirectory for this backup, including if it should be incremental from any discovered existing directories.
- Calculate the keys of the backup data, as well as the time ranges if the backup is incremental.
- Determine the leaseholder nodes for the keys to back up.
- Provide a plan to the nodes that will execute the data export (typically the leaseholder node).
To map out the storage location's directory to which the nodes will write the data, the coordinator identifies the type of backup. This determines the name of the new (or edited) directory to store the backup files in. For example, if there is an existing full backup in the target storage location, the upcoming backup will be incremental and therefore append to the full backup after any existing incremental layers discovered in it.
For more information on how CockroachDB structures backups in storage, see Backup collections.
Key and time range resolution
In this part of the resolution phase, the coordinator will calculate all the necessary spans of keys and their time ranges that the cluster needs to export for this backup. It divides the key spans based on which node is the leaseholder of the range for that key span. Every node has a SQL processor on it to process the backup plan that the coordinator will pass to it. Typically, it is the backup SQL processor on the leaseholder node for the key span that will complete the export work.
Each of the node's backup SQL processors are responsible for:
- Asking the storage layer for the content of each key span.
- Receiving the content from the storage layer.
- Writing it to the backup storage location or locality-specific location (whichever locality best matches the node).
Since any node in a cluster can become the coordinator and all nodes could be responsible for exporting data during a backup, it is necessary that all nodes can connect to the backup storage location.
Export phase
Once the coordinator has provided a plan to each of the backup SQL processors that specifies the backup data, the distributed export of the backup data begins.
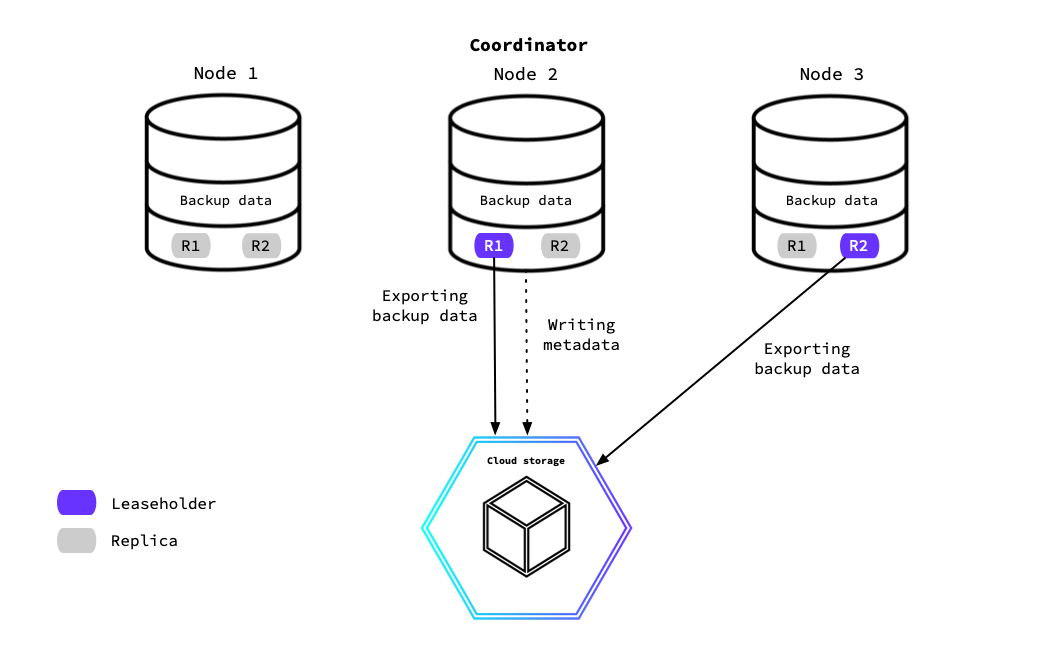
In the following diagram, Node 2 and Node 3 contain the leaseholders for the R1 and R2 ranges. Therefore, in this example backup job, the backup data will be exported from these nodes to the specified storage location.
While processing, the nodes emit progress data that tracks their backup work to the coordinator. In the diagram, Node 3 will send progress data to Node 2. The coordinator node will then aggregate the progress data into checkpoint files in the storage bucket. The checkpoint files provide a marker for the backup to resume after a retryable state, such as when it has been paused.
Metadata writing phase
Once each of the nodes have fully completed their data export work, the coordinator will conclude the backup job by writing the backup metadata files. In the diagram, Node 2 is exporting the backup data for R1 as that range's leaseholder, but this node also exports the backup's metadata as the coordinator.
The backup metadata files describe everything a backup contains. That is, all the information a restore job will need to complete successfully. A backup without metadata files would indicate that the backup did not complete properly and would not be restorable.
With the full backup complete, the specified storage location will contain the backup data and its metadata ready for a potential restore. After subsequent backups of the movr database to this storage location, CockroachDB will create a backup collection. See Backup collections for information on how CockroachDB structures a collection of multiple backups.
See also
- CockroachDB's general Architecture Overview
- Storage layer
- Take Full and Incremental Backups
BACKUPRESTORE
Was this helpful?